🌎第一步:🍭访问美高梅棋牌官网入口官方网站或可靠的软件下载平台:访问(http://xzczwl.cn/)确保您从官方网站或者其他可信的软件下载网站获取软件,这可以避免下载到恶意软件。
🌎第二步:🥇选择软件版本:根据您的操作系统(如Windows、Mac、Linux)选择合适的软件版本。有时候还需要根据系统的位数(32位或64位)来选择美高梅棋牌官网入口。
🌎第三步:⚓️下载美高梅棋牌官网入口软件:点击下载链接或按钮开始下载。根据您的浏览器设置,可能会询问您保存位置。
🌎第四步:💦检查并安装软件:
在安装前,您可以使用杀毒软件对下载的文件进行扫描,确保美高梅棋牌官网入口软件安全无恶意代码。
双击下载的安装文件开始安装过程。根据提示完成安装步骤,这可能包括接受许可协议、选择安装位置、配置安装选项等。
🌎第五步:⛩启动软件:安装完成后,通常会在桌面或开始菜单创建软件快捷方式,点击即可启动使用美高梅棋牌官网入口软件。
🌎第六步:🏔更新和激活(如果需要): 第一次启动美高梅棋牌官网入口软件时,可能需要联网激活或注册。
检查是否有可用的软件更新,以确保使用的是最新版本,这有助于修复已知的错误和提高软件性能。
🗼欢迎使用🔥【美高梅棋牌官网入口】🌎🗻️🌎支持:32/64bit🌎系统类型:美高梅棋牌官网入口(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)创建于2005年,最初只是一个小型的体育资讯网站。经过多年的发展,如今已经成为了国内知名的体育赛事报道媒体。的创始人是一群热爱体育的年轻人,他们深知体育在人们生活中的重要性,希望通过,为更多的人传递体育的魅力。。
✈️恭喜发财🍼【美高梅棋牌官网入口】🌎☕️🌎支持:16/32bit🌎系统类型:美高梅棋牌官网入口(中国)官方网站IOS/安卓通用版/APP下载(2024APP下载)平台汇聚了国内外最新、最全面的体育新闻资讯,包括赛事报道、赛程预告、球队动态、选手专访等,让你随时随地掌握最新的体育动态。。
🛸大吉大利🚨【美高梅棋牌官网入口】🌎⏲️🌎支持:32/64bit🌎系统类型:美高梅棋牌官网入口(中国)官方网站IOS/安卓通用版/APP下载(2024APP下载)平台还提供了多种社交互动功能,包括用户评论、点赞、分享等,用户可以通过这些功能与其他体育爱好者进行交流和互动,分享自己的观点和看法。。
🗼勇闯无限🎈【美高梅棋牌官网入口】🌎🔦️🌎支持:32/64bit🌎系统类型:美高梅棋牌官网入口(中国)官方网站IOS/安卓通用版/手机app下载(2024APP下载)平台汇聚了国内外最新、最全面的体育新闻资讯,包括赛事报道、赛程预告、球队动态、选手专访等,让你随时随地掌握最新的体育动态。。
🏝网页认证🏝【美高梅棋牌官网入口】🌎🏭️🌎支持:32/64bit🌎系统类型:美高梅棋牌官网入口(官方)网站IOS/Android通用版/手机app下载(2024APP下载)未来,将继续坚持自己的特色,不断创新和进步。将会加强与各大体育联盟和俱乐部的合作,为广大体育爱好者提供更加丰富、全面的赛事报道。同时,也将会通过更多的渠道和方式,让更多的人了解体育,爱上体育。。
💰百度热搜🧀【美高梅棋牌官网入口】🌎🥒️🌎支持:32/64bit🌎系统类型:美高梅棋牌官网入口(官方)官方网站IOS/Android通用版/手机app下载(2024APP下载)彩网将持续优化平台,提供更加丰富的赛事内容和更加优质的用户体验。未来,还将加大对电竞等新兴赛事的支持,为用户带来更加多元化的娱乐选择。。
🧸2024百度百科🥇【美高梅棋牌官网入口】🌎🕖️🌎支持:32/64bit🌎系统类型:美高梅棋牌官网入口(官方)登录入口APP下载IOS/安卓通用版/手机APP下载(2024APP下载)的商业模式主要是广告收入和会员收入。通过广告投放、赞助合作等方式获得广告收入,同时也推出了会员服务,为用户提供更加个性化的服务,从而获得会员收入。。
【剑与远征遗忘边陲怎么过 剑与远征遗忘边陲通关攻略******
剑与远征是一款经典的策略卡牌类游戏,游戏里面的副本关卡很多,很多关卡都是比较难的,因为这个游戏需要安装步骤来进行通关,比如这个剑与远征的遗忘边陲关卡,很多玩家不知道怎么过,不知道通关的步骤,那么下面小编就带给大家剑与远征遗忘边陲通关攻略。

奖励介绍:
10占星 2重铸券
2000家具币 100晶碎 50晶核
10红瓜子 20金瓜子 20银瓜子
若干三资箱子



地图导航:
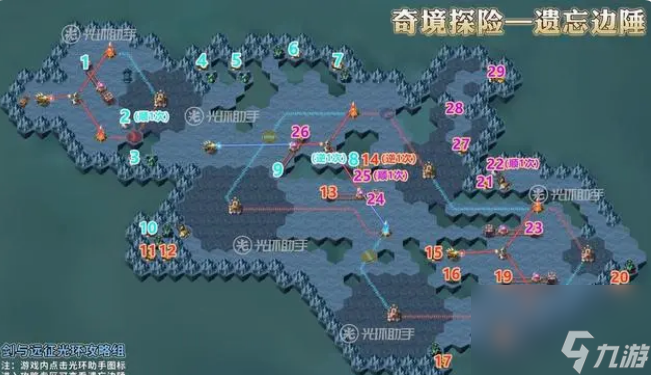
图文详解攻略:
1.到1的位置,使轨道机关往上移动一格
2.到2的位置,使机关顺时针选择一次
3.到3的位置,消灭沿途怪物阵营,获取奖励
4.到4的位置,消灭沿途怪物阵营,获取奖励
5.到5的位置,消灭沿途怪物阵营,获取奖励
6.到6的位置,消灭沿途怪物阵营,获取奖励
7.到7的位置,消灭沿途怪物阵营,获取奖励
8.到8的位置,使机关逆时针选择一次
9.到9的位置,使轨道机关往下移动一格
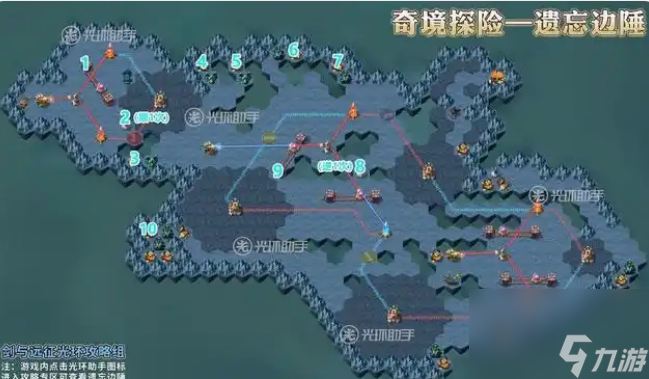
10.到10的位置,消灭沿途怪物阵营,获取奖励
11.到11的位置,消灭沿途怪物阵营,获取奖励
12.到12的位置,消灭沿途怪物阵营,获取奖励
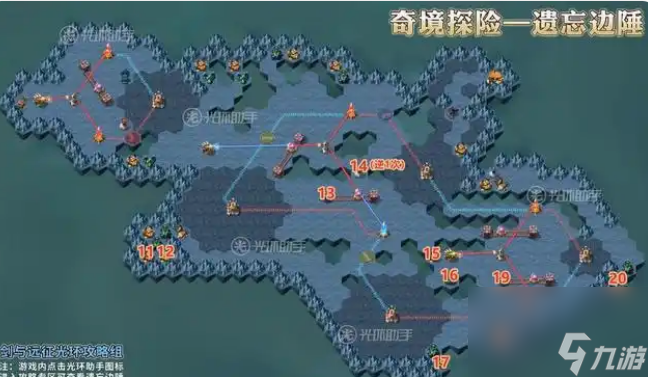
13.到13的位置,使轨道机关往左移动一格
14.到14的位置,使机关逆时针选择一次
15.到15的位置,获取奖励
16.到16的位置,操作机关,使立柱下降
17.到17的位置,消灭沿途怪物阵营,获取奖励
18.到18的位置,消灭沿途怪物阵营,获取奖励
19.到19的位置,使轨道机关往左移动一格
20.到20的位置,消灭沿途怪物阵营,获取奖励
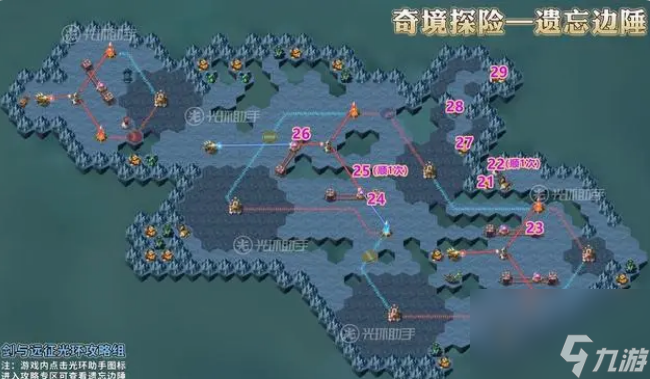
21.到21的位置,获取奖励
22.到22的位置,使机关顺时针选择一次
23.到23的位置,使轨道机关往右移动一格
24.到24的位置,使轨道机关往右移动一格
25.到25的位置,使机关顺时针选择一次
26.到26的位置,使轨道机关往上移动一格
27.到27的位置,获取奖励
28.到28的位置,对话,消灭沿途怪物阵营
29.到29的位置,获取最终奖励
BOSS攻略:
1.打boss前建议存满能量,可留一两关怪物最后打(关闭自动放技能),用来存能量及回血;
2.打boss时可以把光环助手的倍速调慢点,见势不妙重新来;
3.可以提前向好友或公会的大佬借佣兵,推荐使用骨傲天阵容。
】【旅游订单暴涨三倍!这国旅客迷上中国游******
(文/宋虹姗 编辑/赵乾坤)
新加坡旅游与商业媒体Travel Trade Gazette Asia(简称“TTG Asia”)近日报道,希尔顿发布的《2025年趋势报告》显示,2024年底,新加坡人对前往中国旅行的兴趣与热情在显著上升,同时,在线旅游平台上,从新加坡出发前往中国的旅游预订量和搜索量大幅增长。
该报告提到,中国正在成为新加坡游客最受欢迎的目的地之一。数据显示,从2024年12月21日至2025年1月3日的搜索量来看,新加坡游客对北京的搜索量同比增长48%,对上海的搜索量增长81%,对广州的搜索量则增长87%。
报告指出,新加坡的阿尔法世代(Generation Alpha,即2010年后出生的人)和Z世代(1995年至2009年出生的人)中,有23%明确表示对前往中国旅行抱有强烈兴趣。
该报道提到,新加坡振兴旅行社负责人表示,越来越多的新加坡年轻游客对中国的丰富文化遗产表现出浓厚兴趣。例如,古都西安成为他们热衷于探索历史的热门目的地,而新疆、西藏和云南等相对“小众”的目的地也逐渐进入他们的愿望清单,成为备受关注的旅行选择。
该负责人表示, “新加坡人被中国社交媒体上广泛展示的多样化旅游资源深深吸引。中国各地的旅游资源独具特色,能够满足不同游客的兴趣需求。其中,重庆、成都、北京和上海是目前新加坡游客最热门的旅行目的地。这些城市凭借独特的自然景观与繁华都市生活的完美融合,吸引了不同年龄段的游客。”
新加坡丽世酒店管理集团(The Lux Collective)亚太区负责人在接受《TTG Asia》采访时表示,新加坡游客更倾向于选择云南—贵州—四川的旅游路线。云南作为少数民族聚居地,以其独特的自然美景和丰富的地方文化吸引了大量新加坡游客。茶马古道、香格里拉和丽江等目的地尤其受到青睐,成为游客深入体验当地文化与自然风光的首选。
 茶马古道沿线的丽世酒店。TTG Asia
茶马古道沿线的丽世酒店。TTG Asia新加坡游客对中国旅游的热情正在迅速转化为实际的消费。据《TTG Asia》援引新加坡丽世酒店管理集团的数据,从2023年6月到2024年6月,新加坡旅行团前往中国的人数同比增长了五倍。同时,振兴旅行社的数据显示,截至目前,2024年11月至12月前往中国的年终旅游预订量已达到去年的近三倍。
】【原神5.3克洛琳德复刻抽取建议******
原神5.3克洛琳德复刻如何抽取?原神这是一款非常有趣的角色扮演游戏,在游戏里玩家可以看到很多游戏角色,该游戏即将进入5.3版本,届时会迎来很多复刻角色,那么是不是还有很多游戏玩家不知道克洛琳德复刻如何抽取的,今天小编就为大家整理了原神5.3克洛琳德复刻如何抽取的详细介绍,感兴趣的游戏玩家接下来可以和小编一起来看看哦。

克洛琳德作为雷系主C,虽然在输出上有所特色,但并不是非抽不可的角色。
1、克洛琳德是雷系站场主C,专注于自身输出,缺乏后台辅助能力。她的输出机制简单,但对强度党吸引力有限,更适合追求角色设计与风格的XP党玩家。
2、如果你缺少雷系主C,并且喜欢克洛琳德的角色设计和风格,那么可以考虑抽取。
3、推荐按照1命>2命>专武≥3命>4命的顺序进行抽取。

以上就是原神5.3克洛琳德复刻抽取建议的全部内容,更多原神相关攻略,敬请关注本站。
】【艾塔纪元止水武器属性介绍******
为「凝华」特制的阳电子炮,有效弥补了该机体在战场上自保能力不足的问题,在团队作战时也能发挥优秀的支援效果。接下来就由小编给大家带来了详细的艾塔纪元止水武器属性一览,希望这篇文章可以帮到大家!
基础信息:

固定属性:
火力
6.3%
火力
67
耐久
924
效果:
初始EN+100,火力+80,装甲+80,耐久上限+1000,固定伤害+40,固伤抵御+40
※限特种型艾塔装备效果
专属效果:
初始EN+100;每隔15.6秒对当前锁定的敌人附加感电效果,持续8秒,基础效果命中率60%。
※限无波/凝华效果
以上就是艾塔纪元止水武器属性一览的全部内容,更多艾塔纪元相关攻略,敬请关注本站。
】【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】| 翟哲美 | 2025-01-15 |
| 跟看电影一样 | |
| 丘芝兰 | 2025-01-15 |
| 期待这个月接下来的新歌MV希望能达到1点多亿的播放量 | |
| 信兰泽 | 2025-01-15 |
| 佩服梦工厂,不仅仅在技术上,还在于细节处的用心程度,更佩服编剧啊,把传统的太极阴阳图,与国宝熊猫的黑白色联系起来。还有前面两次徒手玩转水滴做铺垫,直接引出后面的徒手玩转炮弹,绝了, | |
| 百成荫 | 2025-01-15 |
| 家园 | |
| 孛梦寒 | 2025-01-15 |
| Official修仙小道童 : 现有的建议小道童都记录下来啦~ | |
| 宓桃 | 2025-01-15 |
| CAST STORY EDlTORlAL ART DEPARTMENT CHARACTER TECHNlCALDlRECTlON MODELlNG SURFAClNG LAYOUT ANIMATION CHARACTER EFFECTS CROWDS EFFECTS LlGHTlNG SPECIAL THANKS SONGS THAT WAS A GREAT AND I HJHJ SOUNDTRACKAVAlLAON SONY HULK HOGAN FOR NOLK @2016DREAMWORKS ANIMATION MEME UK HJHJ HJHJ GHGHGUH | |
| 浦欣愉 | 2025-01-15 |
| 付费收看,还不错 和第一部一样精彩,只是抽取观影券有点扯,好久都没抽到。 | |
| 骑凝海 | 2025-01-15 |
| 看了这么多的评论没有一个人评论到点子上,我感触最深的泪点有两处,总结出来就是,因为爱亲人所以爱祖国爱地球,只有地球祖国好了亲人才会好。 | |
| 逢韵宁 | 2025-01-15 |
| 喵星の野百合 : 你字最长你说了算。好家伙小论文的级别。 | |
| 巢梦菡 | 2025-01-15 |
| Your story may not have such a happy begging,but that dosn't make you who you are.Its the rest of your story,who you choose to be. | |



 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口







































































































































































































































































































































































































































































































































































![2025年006期[方舟]排列三杀码字谜](http://www.www.www.www.www.xzczwl.cn/uploads/images/647870.jpg)
![2025年006期[方舟]排列三杀码字谜](http://www.www.www.www.www.xzczwl.cn/uploads/images/564108.jpg)
![2025年006期[方舟]排列三杀码字谜](http://www.www.www.www.www.xzczwl.cn/uploads/images/854090.jpg)
![2025年006期[方舟]排列三杀码字谜](http://www.www.www.www.www.xzczwl.cn/uploads/images/373658.jpg)
![2025年006期[方舟]排列三杀码字谜](http://www.www.www.www.www.xzczwl.cn/uploads/images/975515.jpg)






















































































































































































































![福彩3D2025年006期[唐伯虎]解太湖真诀 仨肉丸](http://www.www.www.www.www.xzczwl.cn/uploads/images/114914.jpg)
![福彩3D2025年006期[唐伯虎]解太湖真诀 仨肉丸](http://www.www.www.www.www.xzczwl.cn/uploads/images/115272.jpg)
![福彩3D2025年006期[唐伯虎]解太湖真诀 仨肉丸](http://www.www.www.www.www.xzczwl.cn/uploads/images/128705.jpg)
![福彩3D2025年006期[唐伯虎]解太湖真诀 仨肉丸](http://www.www.www.www.www.xzczwl.cn/uploads/images/127255.jpg)
![福彩3D2025年006期[唐伯虎]解太湖真诀 仨肉丸](http://www.www.www.www.www.xzczwl.cn/uploads/images/159397.jpg)



























































































































































































































































 293535
293535 8935346
8935346


